Now that we have a couple of successes under our belt, perhaps we can tackle something more ambitious. Maybe we can do something more intelligent with "attention" than just search for context. Attention involves the active promotion and inhibition of perceptual channels based on relevance (which is related to both value and interest). It uses the context from scene mapping to guide eye movements and control the gain through visual channels.
At this point we have a working compactified timeline that can store and retrieve episodes, but as a robot it not yet act independently, thus we have simulated "episodes" as moving visual scenery. However in real life an episode might involve navigating a maze, or solving a puzzle. Episodes can be goal-driven, and acquiring (or failing to acquire) the goal can end an episode. Attention is closely related to the organization of episodes. Between episodes, almost by definition, there is nothing to pay attention to.
In our model network, the goal is "visual exploration", that is to say, deriving the maximum amount of information from the visual scene. We'll stipulate that a scene is larger than an image, in both space and time. Eye, head, and body movements will be necessary to navigate a scene. We can create specific sub-goals in the form of ordered graphs, for example we can tell our robot to sequentially search for particular objects in the visual field.
Attention - The Machine Learning VersionThe prototypical example of attention in machine learning is understanding and generating spoken and written language. A neural network can learn to predict which word comes next, but many words are ambiguous (like the word "apple"). The method of the attention system is to disambiguate the meaning of a word by searching for context in neighboring words. The machine learning version of attention includes the well known and very successful "transformer" architecture.
We need to spend a little time discussing the Bayesian method underlying much of machine learning, because it's important when we wish to understand the relationship between brain models and machine models. Bayesian learning is a method, rather than a mechanism. The method can use many possible mechanisms. Bayes' Rule is:
posterior = (likelihood * prior) / evidence
P(Θ|X) = P(X|Θ) * P(Θ) / P(X)
where P is probability, Θ is our model, and X is the data.
In repeated learning trials, we adjust the model Θ to match the evidence X. Generally Θ has a large number of parameters, and each data point Xi is a vector containing a lot of information. There are many methods available to organize the data in such a way that we can extract and visualize relationships. Some of these methods are friendly to neural networks, some aren't. Methods that are useful for machine learning may include principal component analysis, nearest neighbor analysis, function approximation, and so on. A thorough introduction to machine learning is beyond the scope of these pages, but there is plenty of information available online, including the excellent courses by Stanford University. I'd also recommend learning the basics of Bayesian inference, at least up until the introduction of gamma and beta functions as conjugate priors.
Attention - Our VersionIn our version of attention, we'll also be interested in the relationship between data points, however our meaning reaches a little deeper than the machine version. For neuroscientists, attention involves "selective" attention, which in our context means scanning the portions of the visual field that are most significant and most informative. "Most significant" may include things like threat avoidance, or the location of rewards in a maze. "Most informative" may include the portions of a piece of art that contain the most detail or the most ambiguity.
In a good world, we can design an attention system to fulfill both functions. Using the compactified timeline model, we can easily see how relationships in a sequence can be extracted (an example was show in the first section). However there is a twist now. The information coming out of our memory system has been phase encoded. This means it's in the form of little snippets of time relating "mini-sequences". We will attempt to leverage this organization in our attention system, because it's actually very close to what we need to do in causality analysis.
We'll also note here, that our attention architecture is kind of "halfway" to a full topological embedding. And this is consistent with the way the brain is known to work, for example representing complex shapes as stick figures composed of more primitive shapes. We'll thus wish to investigate whether our attention system can serve as a bridge between the timeline and the global workspace.
The first thing we can do is set up a proper embedding network. This is a considerable task. In the simulators we've seen so far, there is no convenient way of implementing thermodynamic networks. Part of that is because the simulators come out of the neuroscience world, where global signals are frowned on and everyone searches for local mechanisms. The Nest simulator is unique in that it has a number of models that handle astrocytes. Astrocytes are (or can be) "regional", not fully local, and not fully global. However they are interconnected by gap junctions, and it's possible and even likely that they form an electrical syncytium in areas of the cerebral cortex.
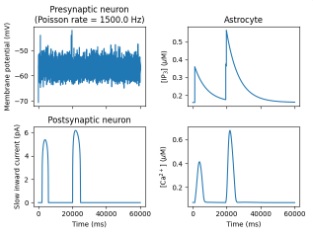
Another part of the issue with thermodynamic network is that the simulators work on "ticks", they're discrete-time approximations of continuous processes. In many cases this makes it easier to numerically solve the differential equations, but it wreaks havoc on the thermodynamic networks because the updates have to be accomplished asynchronously. One can't tell most simulators to "choose the next neuron to be updated". If we really want to do this inside a tool like Nest, we have to write an extension, which could be a plug-in or a compiled module. This is a bit painful, a little code is okay but a lot is too much. So how do we do this? Well... the short answer is... we're SOL. We're asking the simulator to do something it does well (which we know because we've already done it), and something it wasn't designed for. Unfortunately, there isn't a simulator that will do both of these things at the same time. The cheaper and easier way at this juncture, is to write our own code in NumPy. Oh, the horror... But before we abandon this effort, let's see if PyTorch or TensorFlow can do something for us.
Hopfield networks in PyTorch are pretty easy. Here's how you do it:
from HopfieldNetworkPyTorch import HopfieldNetwork, ModernHopfieldNetwork
# Initialize a traditional Hopfield Network
hopfield_net = HopfieldNetwork()
That's it, that's all. Easy peasy. Building a timeline in PyTorch though, is a little harder. Here's how you do it. It's a lot of programming. This is what we were hoping to avoid, by using simulators with friendly GUI's. Unfortunately there's no better way, not at this time. Brian2 has the same conundrum, it lets you have amazingly fine grained control over your membrane properties, but you have to program everything, even the units. The distance between conceptualizing a network and programming it, is a bridge too far for many researchers. Biologists don't necessarily want to become machine learning engineers "too". (It's bad enough we have to learn statistics lol). So at this point, having surveyed many of the tools available to us, we can definitely state unequivocally that there is a gap in the software space, for these types of modeling efforts. This gap is technologically complex, it's not something a hot-shot programmer can fix overnight. Just to get the geometry into a form that's usable by scientists, would be a multi-year effort by multiple people. It makes no sense to write another simulator, the existing ones are fine (at least insofar as they don't crash all the time). A good effort though, would be to choose your favorite simulator and expand it. Because as you're going about your modeling work, you're going to do that anyway. You'll have to, it's part and parcel of the effort. So, become a contributor. Pick a simulator and get to know it "real good". Once you do, the team will welcome you and help you with your contributions.
On To Attention, Then...There are still plenty of things we can do with attention, without a full-blown model. A simple form of selective attention in the visual system is blocking out the periphery, so we can devote our computational resources to focusing on objects in the foveal region. If the edges of our visual map were compactified, we could do this very easily with a single gradient of inhibition. The mapping of the visual field in both V1 and SC has a complex-log character, where the foveal region is on one end of the mapping and the periphery is on the other. This being the case, all we have to do is mask off the anterior portion of V1 or the caudal portion of the SC. This would require a gradient of inhibition from peripheral to central, and there is definitely such a thing in the SC, and very likely in V1 too (and in subsequent retinotopic maps, in V2 forward). In humans the pulvinar (in the thalamus) regulates selective visual attention. It receives input from both visual streams, including peripheral areas like the LGN and the SC, and it communicates with the parietal lobe and the frontal eye fields, both of which are also part of the dorsal attention stream. In the anterior portions of the brain, the mediodorsal nucleus of the thalamus regulates the interplay between working memory and episodic memory, the ventromedial prefrontal cortex is more closely associated with the scene map, while the dorsolateral prefrontal cortex is more closely associated with the motor actions related to working memory. Both areas are important for navigation, without them the success rate for spatial working memory tasks goes way down.
"Objects", in visual space, are connected, their pixels are colocated and move together. Objects can be localized using the "hot spots" discussed earlier. The result is a sparse topographic map indicating the location of objects in egocentric visual space. Such a map can then be used to target eye movements to these objects, subject to selective visual attention. Is there an "algorithm" for attention? What determines the next thing we pay attention to? Psychologists have defined certain relevant aspects of attention that a neural network model has to handle, and certain peculiarities of human behavior that an accurate model should mimic. Some of the psychological models include Broadbent's filtering model, Treisman's attenuation model, and the Central Bottleneck theory (Ruthruff and Pashler 2009), and related behaviors may include change blindness, inattention blindness, multitasking costs, and the Stroop effect related to conflicting information (cognitive interference).
One of the essential things we can learn from the machine side, is the importance of graph neural networks (GNN's). These networks are exactly what they sound like, they're neural networks that represent and operate on graphs. What are graphs ? Graphs are data structures with vertices ("nodes") and edges. In other words, they look just like neural networks. Graph structures are shown below. The edges can be symmetric (undirected), or asymmetric (directed). Graphs are useful for many things. In general they represented objects (nodes), and relationships between objects (edges). (In this usage an event is an object too, same thing). As we'll see shortly, graph neural networks provide a rationale for phase encoding, a reason for its existence.

For each node in the graph, one can construct an adjacency matrix. This is a map of all the other nodes it connects to (directly). If there are N nodes, the adjacency map is an N x N matrix. Each row of the adjacency matrix represents a node. We put a 1 wherever there is an edge, and 0 when there is no edge. For a symmetric graph the adjacency matrix is also symmetric. An asymmetric graph without recurrent paths is called a directed acyclic graph (DAG).

In a graph neural network (layer), the adjacency matrix is used to weight the connections between nodes. Since the adjacency matrix only represents direct connections, information only takes one hop at a time. The terminology used in the machine learning world is "message passing", but this is redundant. All neural communication is "message passing", in the form of spike trains and synaptic activity. What's really going on here, is the machine learning people are trying to tell us there is a need for additional dimensionality in the neural encoding. Which is something that phase encoding brings to the table. Traditionally there is the time to first spike, time to burst, average firing rate, burst rate, and so on - these are the dimensions of variability in a neural signal. Phase encoding is another dimension, a way to "distribute" the information in the network, in space as well as time. Really this is just an extension of the idea of lateral connectivity, which includes recurrent lateral connectivity, and even recurrent self-connectivity in a graph convolutional network. In a GNN, message passing means that each node acquires information from its nearest neighbors, and conversely this means that the information from each node starts spreading through the network, one hop at a time. When a cost function is applied to this behavior, the network will eventually reach an equilibrium that comes to "represent" the graph - which means its topological structure as well as its algebraic structure. Graph neural networks are important in the elaboration of motor behavior, and they are instructive to study in the context of attention, because we can begin to see what phase encoding is for, and how it might operate in terms of an interface to the global store.
Having understood this architecture, we can easily see how it can play into the landscape of attention. Objects are in a scene, and there are relationships between objects (at a basic level, relative positioning, and perhaps meaningful relationships at the semantic level as well). Those relationships can be represented in the form of a graph (or multiple graphs). The edges in the graph are effectively the "context" for each object, that is to say, its relationships. Phase encoding distributes the relationships in both space and time, by including micro-sequences of relationships in particular positions of the spike train. When two objects are related they will "move together" in the information space, in exactly the same way they would move together in the visual space if they were related. Thus the relative positioning in the spike train will remain relatively stable as the organism navigates through the environment. Thus the spiking phase represents a relationship - it encodes the sharing of information between neighboring nodes.
When the graph is symmetric, its adjacency matrix can be diagonalized and the eigenvalues applies to further calculations, like the length of an edge. Mathematically a graph consists of a set of vertices and edges { V, E }. This representation closely resembles the idea of a "mesh". (We saw an example of a mesh earlier, when we looked at Annie's picture of a neural network, and its import into Blender). A mesh is a graph, but it can be cyclic. It consists of vertices, edges, and faces. The faces are defined by normal vectors that point outward from each face, which describes an orientation relative to the embedding dimension. Faces can also be internally oriented, as described in the Grassmann algebra. If the faces are triangular, global orientation can always be achieved, and it can sometimes be achieved for other polygonal structures. As distinct from a mesh, a point cloud has no edges, and therefore no faces. However these can be "built", based on the relationship between nearby points. In the same way, neural networks can build associations (edges) between events by analyzing their phase encoded temporal relationships. When the ramp cells in the entorhinal cortex operate with periods much greater than the theta rhythm, such a method can be used to solve the credit assignment problem, using the micro-causality method shown in the first section. And, as discussed, this amounts to a grand total of rotating a circle, which is simply a matrix multiplication - something neural network excel at!
In the case of attention, the graph that results from the loading of contextual information is used to pass that context between nodes, allowing decision making on the basis of combinations of events. In the case of motor mapping, the graph is directed and asymmetrical, meaning that sequences have a well defined orientation. The directed acyclic graph is also of fundamental importance in the cognition related to causality, which is central to solving goal oriented tasks, and also central to the modeling of belief. Directed acyclic graphs provide a convenient way to manipulate the parameters underlying Bayesian inference on a dataset, the dataset in this case being the moving signal patterns along the timeline, and the conversion of this signal pattern into timeless representations in a mathematical graph. The graph can be high dimensional. There is nothing restricting the graph to 3 dimensions. One must be careful because there is sometimes slightly different algebra in the higher dimensions, and tools like the Clifford algebras become useful to us because we have to deal with both commutative and anti-commutative operators.
Next: Model Results
|