At this point we have a linear timeline, consisting of an oculomotor system and a visual system. However we have no memory! That is, we haven't yet organized the nature of the memory, and regulated the access to it. One can't simply throw in all possible forms of memory, each kind has a purpose and so we engineer the neural network to address the required information.
For our visual memory system, we'll need to do two things. One is, we'll need working memory so we can build an attention system. Second, we'll need episodic memory so our robot can navigate the world. To accomplish the second piece, we will attempt to phase-encode the left end of our timeline in much the same way that the human hippocampus phase-encodes signals relative to the theta rhythm. In doing so, we will need to build the allocentric reference frame that results in grid cells, ramp cells, place cells, and time cells.
This is a good place to introduce yet another simulator - in this section we'll take a look at Nest, an excellent simulator that's current and being actively maintained. The best way to use Nest is with a Docker image, it's a quick and painless install and it'll leave your system unmolested when it exits. Nest has a superb user interface, it's a little confusing at first but after reading the documentation things become a lot clearer and you can start using it right away. This is what a neuron definition looks like in Nest:

Now that's more like it! Everything is clear and intuitive - and simple! Let's see what we can do with this.
As far as we know right now, memory is all about synaptic plasticity. But what happens in brains, is quite different from what happens in machines. Some of you have probably taken Andrew Ng's excellent machine learning courses online (the ones from Stanford are available on YouTube for free), and learned all about logistic regression and the ways in which "learning rules" at the synaptic level enable very powerful behaviors at the network level. Some of the simulators like Brian2 are focused at the neuron level, maybe even patches of membrane, and such calculations aren't much amenable to GPU acceleration - and as already emphasized, the network geometry is vitally important and in real brains we hardly ever see "flat sheets of neurons", most of the time they're organized in a modular fashion and the modules can get pretty complicated. On the other hand Nengo lets us lay out multi-dimensional arrays (even though it's hard to look at them) and play with machine learning in the very same user interface that lets us alter synaptic behavior.
One of the glaring problems with many simulators is they don't let us handle smart inhibitory neurons. In Nengo you create an inhibitory neuron by telling it transform=[[-1]], whereas in Brian2 it's a differential equation that affects chloride ions or something. It would be nice to have something in the middle. We need a catalog of biologically real synapses to draw from. Give me... an AMPA receptor on this connection, and an NMDAR on this other one. GABA over here, and a gap junction over there. 'Nuff said, let's go.
It should be that easy! Now... in the real world, different simulators are good for different things. Topographica is no longer with us, and it left a bit of a vacuum when it went. Neuroscience is an interesting community, some people think bottom-up, like they're focused on neurons and synapses and patches of membrane, and when they hear "glutamate" they start thinking about time constants. Other neuroscientists are more interested in the cognitive side, they'd like to know about things like episodic memory and its relationship to clinical conditions. Me... I've used PyTorch and TensorFlow, and I hate them both because they're so... well... "machine"-y. I like their layouts though. They're a whole lot better than what we can conveniently do with most neural network simulators. My own research is at the network level - halfway between the neurons and the whole brain. I'm interested in what new and exciting neuron behaviors can do for my network. Spiking dendrites, for example, add new behaviors to a network, they can turn every neuron into its own little convolutional network, and the question is, "how can I control that behavior with network dynamics?" I'm not going to pretend to understand time constants ahead of time, if I understood them I wouldn't need a simulator! Instead, I'm going to define the network architecture first, which is probably the best known piece in most cases - since we have several hundred years of anatomy on record - and then I'm going to play with the time constants till I get the behavior I want. I don't like animal experiments, I'm not going to kill any rats (or ask anyone else to) till I'm crystal clear on what I'm looking for. And, if my simulator can't support the required behaviors, or the required network layout, then it's not a very good simulator is it.
Working MemoryLet's begin with working memory. That's probably the easiest kind, perhaps the best understood in many ways. Working memory is the opposite of gradient descent, it's a very fast and reversible process that happens instantly, and in one shot. Whatever you're experiencing right now, you're going to remember it for at least a few seconds. Working memory does not involve the permanent burning in of synapses like machine learning does. Instead, the evidence is that sequences of experience are phase-encoded in the frontal lobes of the human brain. There is unquestionably "reverberation" of sorts, and one of the interesting aspects of it is the sequences of input get replayed in both forward and backward order. You'll recall we discussed this phenomenon earlier, in the very first section, and showed how it could be made to happen with a simple geometric (topological) twist to an ordinary linear timeline. This is only one of many reasons why the network geometry is so important.
It is somewhat unclear how long working memory has to last. It certainly has to last long enough to service an attention mechanism, which probably means on the order of seconds to minutes. This can be accomplished in a variety of ways, and it's not entirely clear which way(s) the brain uses. One could use any of the forms of synaptic plasticity, and one could also maintain wave-like behavior in the network (like liquid state machines). For our purposes, individual memory traces need to be recoverable in a time frame of... say... 30 minutes. For this purpose, a synaptic mechanism seems best. However it requires a control circuit, because memory needs be buffered (it needs to be "erasable"). In humans, a new and important experience will often cause a complete flushing of recent memory (one psychologist calls it the "now where was I" syndrome). And we also know there's an upper limit to the amount of information that can be handled at once (that was George Miller - " the magic number 7, plus or minus 2").
A key concept in working memory is "one-shot learning". In other words, it should only take one presentation of the stimulus to remember it. Machine learning that requires a thousand presentations of the same stimulus isn't going to work for us. Fortunately, a predictive coding architecture will handle this for us, subject to some important constraints. Neuroscientists will immediately realize that a predictive coding "module" that could work for this purpose, requires a lot of neurons, and some pretty idiosyncratic synaptic behavior. Not only that, but the network has very specific architectures, for example there are inhibitory neurons whose sole purpose is to keep a pyramidal cell from spiking - such neurons can be wrapped around the base of an apical dendrite, or even the action potential generating region of the axon hillock nearest to the soma. Quite obviously (from the architecture), these neurons need to be able to learn. And there are other important non-pyramidal neurons with plenty of dendritic spines, that are undoubtedly engaged in plasticity as well - they go by names like "spiny stellate cells", and sometimes they send their axons over long distances.
To help us create our network, the Nest simulator has several different kinds of visualizations, including the generation of publication-ready network graphs exportable to Libre Office. Some of these are still in development (or re-development), but we can still take a look at them. Here are some examples:



These are nice capabilities, but we'd like to see the results of our learning experiments in a more intuitive manner (like Brian2's ability to learn its own name, that was excellent). The Nest simulator claims to follow the standards of Senk et al 2022, which is somewhat suprising because those standards are clearly focused on presentation graphics and not on scientific visualization. That's probably because scientific visualization is hard. It's very, very difficult compared to presentation graphics - and it takes a lot of programming time, and sometimes AI even has to get involved. (Like the AI-enhanced picture of the fruit fly on the earlier page, did you like that?) Unfortunately, Nest doesn't have any convenient export capabilities outside of the presentation graphics range. Nest will save data - spike trains and so on - but it won't export the network structure to Python or OBJ or XML. And Annie isn't interested in data, and doesn't know what to do with it. It's only interested in network geometry, and it will carry details of the components to the extent that they're supported by the various modeling tools. (We should mention here, that another simulation environment called NeuroML will serve as an XML interface - however as a neuroscientist I feel XML is painful and I'd rather not have to spend time counting a bunch of angle brackets - nevertheless, XML is a standard form of interchange for many systems, even though very few of them are dedicated to network visualization).
There's another oddity about Nest, which you can see here:

Look at the last section, the one labeled "update". You see the problem? Refractoriness is in fact a consequence of the differential equations, we're not in a position to make that decision on behalf of the neuron. But other than little peculiarities like this, the programming is generally good, and it's more useful than either Brian2 or Nengo. (Brian2 because it's too complicated, even though in theory it gives us very detailed control over membrane properties - and Nengo because it's too simple, we can't do many clever or sophisticated things with the canned synapses and transforms).
In most simulators, synapses are modeled by simple differential equations that mimic the time course of postsynaptic currents. It's worth surfing around a bit to see how people handle this. A good resource is the neuronal dynamics book from Gerstner et al 2014, which is in the bibliography or here. It has an excellent discussion on the subject of synapses.
Phase EncodingThis is a good place to talk about phase encoding. What is that exactly, and how does it work? And how does it help memory?
(phase encoding)
Memory storage and retrieval seems to be related in many ways to brain rhythms. In particular, the areas around the hippocampus that support a "spatial-cognitive map" are organized by a theta rhythm generated in the medial septal nucleus.
(more phase encoding)
Here is an example of a network generated by Nest.
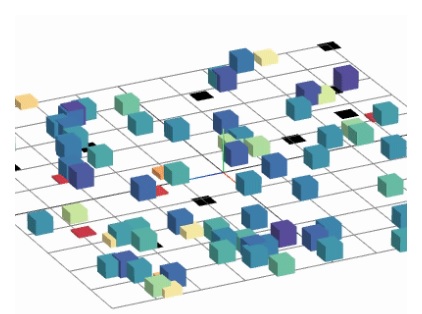
It's not bad. It's missing the global network topography, but it's showing us a "module". If we wanted to build a cerebral cortex, we could replicate this a few thousand times and figure out how to wire the modules together, and thus we could create a pretty effective geometry. This particular module is not yet at the level of predictive coding (there are too few neurons), but it's getting there. And from the annotation you can see this could easily be expanded with 8 or 10 more neurons. Which may seems like a lot, but keep in mind that the earlier effort with the retina involved 40+ different kinds of amacrine cells and 20+ different kinds of ganglion cells, just to get a visual signal into the brain. There is no shortage of cell types in a human brain!
Here's what Nest-generated code looks like:
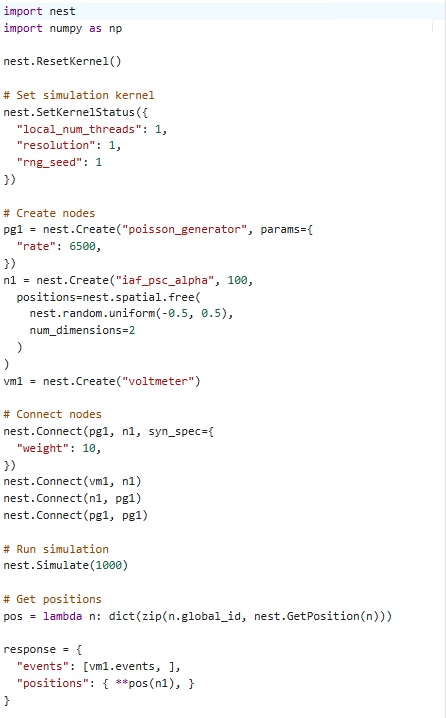
Note that some of these simulators use strange vocabulary. Like "nodes and edges", instead of cells and synapses. In Nengo a node is something different from a neuron, it's what Annie calls an "External", so for instance if you were modeling a retina, the light would be external and the optic nerve would be external. You can kinda tell what an input node is doing because it has some sliders right next to it, which should tell you it's expecting you to set them. And an output node shows up as a black dot, to indicate there's no input required. It's kinda weird when scientists create a "neural network" simulator and then call its components something different from neurons and synapses. It's almost like they're telling you, what we have here is "close" to a neural network but not exactly that. (If they don't claim to be a neuron no one can sue them, right? ;)
Here's the thing - phase encoding involves traveling waves. How are we going to look at that, inside the simulator? Well, here's one of the good things about Nest:
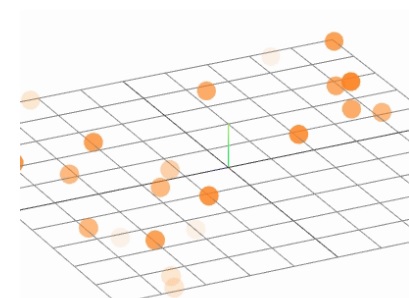
In the simulation, the little bars move up and down, so you can see where the activity is. And you'll note, the whole thing is on a 2-dimensional grid. This is "almost" like Annie's hot-cold map, it's a very useful display. If we set up the theta rhythm correctly, we should be able to see a big fat beautiful traveling wave moving across the network. Here's another interesting display - not quite as useful perhaps, but relevant nonetheless. In this one, the little orange balls represent spike times, and the darker they are the more intense the spiking activity.
This is all good - let's see how hard it is to set up a 2-d network, and then how hard it is to feed a theta wave into it. It turns out, setting up a 2-d or 3-d network in Nest is pretty easy. You can do it in a grid layout or with a list of points. The theta waves are a little harder, because they're traveling waves. There is a thorough description of Nest's geometric capabilities on the documentation page about spatially-structured networks. Nest is a powerful simulator, it has an extensive library of a hundred or so neuron types, and all kinds of examples with intricate synaptic behavior like AMPA and NMDA receptors. Nest even has a primitive concept of compactification! They call it "periodic boundary conditions", which certainly doesn't do justice to the importance of the issue. All it is in Nest, is wrapping the edges of a network so the boundary neurons still have the right numbers of neighbors. Which is something quite different from adding a point at infinity. It may look the same to the untrained eye, but the results are definitely not the same! To prove it, let's take a look at episodic memory, and see if we can do some phase encoding. Meanwhile, here's another nice display from Nest, and the code that generated it. This is a map of the spike trains of 10 neurons, fed by a Poisson generator with a controllable rate. The histogram is showing us the number of spikes in a time interval, and as neuroscientists we'd also like to see ISI and PSTH (inter-spike interval, and peri-stimulus time histogram), because we're familiar with those formats. This is very nice though, clean, intuitive, ready for presentation with a few minutes additional work.
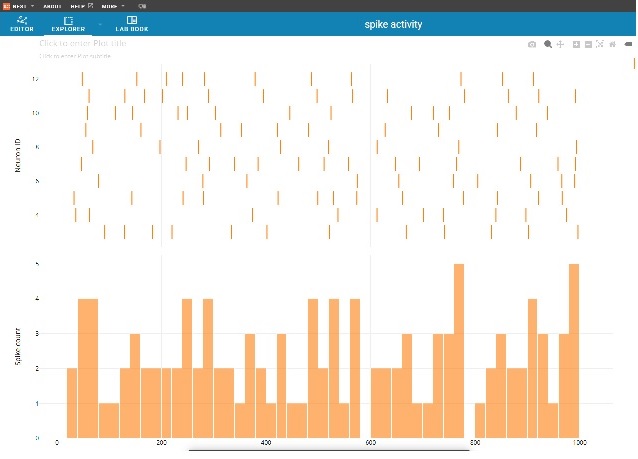
Episodic MemoryEpisodic memory is different from working memory, but the two are closely coordinated. The focus in studying episodic memory has mostly been on the input side, but episodic memory draws contextual information from both working memory and the global store. At least a portion of this access is controlled through the prefrontal cortex (PFC). Let's set up a tiny hippocampus inside Nest, and see if we can apply a theta wave to it. We can begin by copying the grid layout from the examples, there are pyramidal cells and interneurons. Next we find a sine wave generator. We have two choices, either apply an AC signal to an intermediary neuron so we get a nice clean output, or load a spike generator with an array of times corresponding to a sine wave. The first method is easier. Here's a sine wave, and the code that created it.
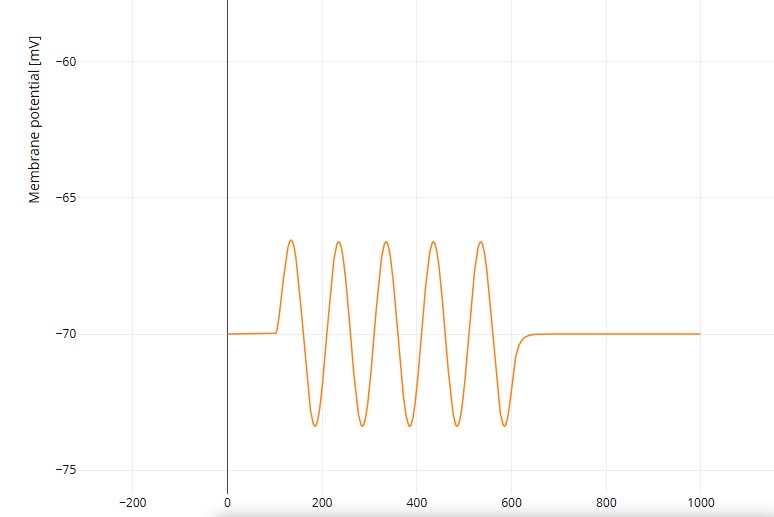
That was easy. We can run this through a neuron to get a spike train. However now we have a problem. We need to apply this signal as a traveling wave, to the group of neurons we created above. We have to stagger the phase of the sine wave, so it's properly applied to each location in order. We can fake this with multiple generators, Nest provides us a way to do that, but a better way is to use neurons to do it. An easy way is to use a chain of neurons with a small synaptic delay, but a more brain-like way would be to create a small medial septal nucleus, with a population of neurons that supports topographic wave-like activity.
Our goal here, is mainly to investigate the synaptic plasticity in the hippocampus. So for purposes of a demo, we'll use the quick and dirty method and simply apply the wave by hand (since we have very few neurons). Let's look at our model hippocampus. There are two types of neurons, pyramidal cells and interneurons. The interneurons are inhibitory, and they conform with the simple motif shown earlier. Let's see whether we can first get the pyramidal cells to memorize something. We need plastic synapses, and part of the idea is to experiment with various synapse types to see which combinations of receptors give us the desired behavior.
For instance, we can set up STDP synapses in Nest this way:
nest.Connect(
nrns[:5], nrns[:5], "one_to_one", {"synapse_model": "stdp_synapse", "weight": nest.random.normal(mean=5.0, std=2.0)}
)
To get neuron behavior, we can become advanced Nest users and investigate the NestML modeling language, which has a tremendous array of useful neuron types and behaviors.
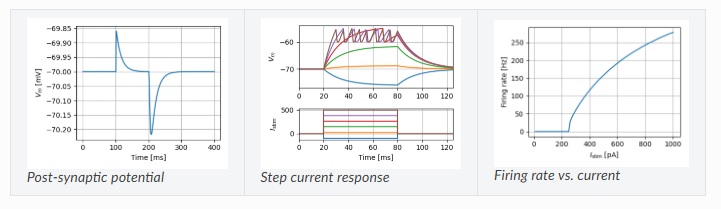
With Nest and NestML, we can run compartmented neuron models with active dendrites.
To get separability in the pattern space, we need to play with the nonlinear threshold functions, for both neurons and dendrites. Since we're using STDP, we can use any of the spiking neuron types, anything from integrate-and-fire to full-on Hodgkin-Huxley. For the sake of runtime performance, we can begin with the integrate-and-fire model, which is fast and easy to compute although limited in capability (and it can introduce artifacts too, which we'll have to watch out for - especially at high frequencies).
Assuming we have a useful network and we can apply theta to it, our next effort will be to visualize the results. It's hard to tell what a spike train means by just looking at it, so we'll probably want something more like the hot-cold map that Annie gives us. To get this, we can export the spike trains in Ascii form from Nest, and import them into Annie, and ask Annie to visualize them for us. However even with great graphics these neuron activities don't tell us much, because they're encoded statistics of the input. To determine whether the network is working properly, we need to build some inputs with contrived statistics. In this case, we're specifically interested in the timing of spikes with respect to the theta rhythm, and we can model the ISI's so they predict the synaptic modifications. This is a crude and expensive way to "decode" the weight matrix after learning. An easier but even less informative way might be to do some quick exploratory data science with R language or Pandas.
As a basic framework, we can begin with NestML's sequence learning example, and expand it to include the features just mentioned. After all is said and done, we end up with results like this - here is an example of a neuron learning a spike train, on the basis of STDP plasticity in the active dendrites:
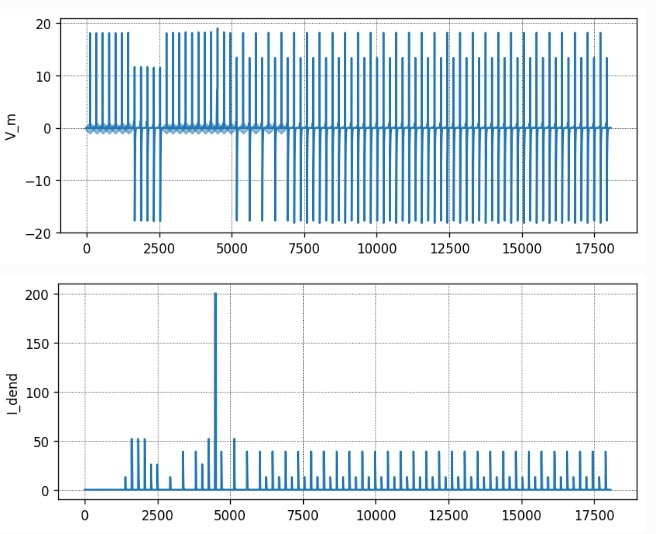
That's all we need, we have a working model. From here we can expand it in any direction we choose. You can see that Nest is flexible and powerful. It's still somewhat crude with its geometric handling, but there are signs it recognizes the issue and is moving towards enhancement in that direction. An example is the "Connection Set Algebra" module (Djurfeldt 2012), which still requires a C++ compiler but will eventually work in Python too. The CSA is powerful if somewhat abstract, for example it lets us connect "modules" (columns and hyper-columns) in an intelligent way, much the same way as Annie does. Annie will import and export Nest code, and when CSA becomes available in Python it will handle that too.
Next: Attention
|