The prototypical machine learning model for data-driven self-organization is the Perceptron. There are multi-layer Perceptrons with extensive feed-forward connectivity, and convolutional networks are basically Perceptrons with restricted connectivity and a little extra computational power. Perceptrons learn linear separability on the basis of the statistics of the input. When the threshold functions are made more complex, sometimes a limited amount of nonlinear separability can be acheived, but Perceptrons are generally very simple devices.
There are different kinds of data-driven self-organization ("learning"). The architecture of a neural network (for biology or machine learning) depends on the goal. If the goal is to classify images, one will probably engage in a supervised learning method, where a "correct answer" is known in advance. (If the network has to distinguish cats from dogs, a programmer or "teaching signal" can be made available to tell the network "this one is a cat"). On the other hand, human beings never know in advance how many images they may encounter, or how those images might be organized. Nevertheless, there are certain properties of images that are so basic and universal they hardly seem worth mentioning, except that they turn out to be vitally important. For one thing, the image is always presented as a unit. (This is true for both humans and machines!) In computer graphics this concept is called a "frame", and the sampling rate of successive frames is measure in frames per second (fps). In most machine vision architectures, the sampling of frames is synchronous, images are like "snapshots". Whereas, in human beings, sampling may be considerably asynchronous, and because of this may become approximately continuous over a population of neurons. In humans, sampling is synchronized through population behavior, frequently through lateral inhibition. There is also coordination at the level of entire networks, for instance visual sampling is guided by intermittent eye movements and eye blinks. In a situation where the number and character of images is not known in advance, one may choose to use an "unsupervised" learning method. Strangely enough, a reward can serve as a supervision signal, so when we're trying to relate the machine learning vocabulary to psychological terms like "Pavlovian conditioning" and "operant reinforcement", one must realize that the former is unsupervised because it's freely associative, whereas the latter is supervised because it depends on a training signal (even when the training signal has to be "discovered").
When it comes to engineering neural networks, the machine learning community is focused on performance, and in this focus it pays attention to things that neuroscientists often leave till the last minute. From a development standpoint, this is akin to error handling, it's something one wants to do up front and consistently, otherwise once the system gets complex one might find one has to take the whole thing apart again. Machine learning depends heavily on non-biological mechanisms. There are some very clever learning rules invented in the machine learning community, that have no counterpart in the brain (or at least, none known so far). However machine learning informs us about the vital character of the data, and that different strategies work well with different kinds of data. Machine learning and data science are closely related, many of the same techniques are in use.
When considering the brain from a real-time standpoint, we're probably less interested in invariances and more interested in the ability to precisely time motor behavior. Nevertheless invariances are an important study, especially in the visual system. The particular motor system we looked at (the oculomotor system) does not always require precise timing, in most cases the timing is either reactive or voluntary. (Nevertheless we've seen how rapid movements are coordinated). In relation to the real time brain, we might be more interested in the piano player or drummer, or the basketball or ping pong player. The good news here is that we can use relatively simple tools to begin experimenting, like video games and brain-computer interfaces. This discussion eventually leads to an understanding of navigation, and directed acyclic graphs. We'll elaborate those concepts in this section.
Data StorageYou may already be familiar with terms like facilitation, augmentation, and potentiation from the biology literature. Similarly their counterparts, adaptation and depression. Each of these terms has specific meaning, but generally they all revolve around either pre-synaptic or post-synaptic modification of synaptic transmission. Pre-synaptically, regulation of transmission can be accomplished by a change in the number of vesicles released, or a change in the amount of transmitter per vesicle, or a change in the relationship between voltage and release kinetics. Postsynaptically there is the number and location of receptors, the coupling between receptors and ion channels, and the relationship between receptors and second messengers.
To begin with, one can consider the division of plasticity into short term and long term types. Short term is designated as minutes or less, whereas if the modifications last more than an hour they're usually considered long-term. The division is somewhat arbitrary, it's better to think in terms of the time constants and the way they relate to each other. In the case of increasing transmission, facilitation is typically on the time scale of milliseconds to seconds, augmentation in the range of seconds to minutes, and potentiation occurs on a longer time scale of minutes to hours. Facilitation is typically driven by short term ionic mechanisms, like an influx of calcium that increases the probability of vesicular release. On the other hand potentiation can engage the mobilization of reserve vesicle pools, an effect that can last for many minutes and may involve protein kinases and other messenger-driven activities. Facilitation follows rapid signaling (it's usually tested with paired pulses), whereas potentiation follows intense high frequency stimulation (like electrically induced tetanus). The extent to which these phenomena are important for network behavior depends on the connectivity as well as the chemistry. Sometimes these behaviors can be introduced at the synaptic level with little or no change in the network behavior, and other times they have a dramatic effect. Generally the effect is larger in populations that are heavily interconnected.
Going the other way, there is adaptation and depression. Adaptation is mainly a postsynaptic process involving calcium-dependent and voltage-dependent potassium channels that self-inhibit the neuron, leading to a decrease in firing frequency. Adaptation can be helpful for gain control and novelty detection. On the other hand, depression may involve the depletion of presynaptic vesicles, causing the synapse to temporarily weaken or fail. Depression is classical STD, it helps with noise reduction by acting as a high pass filter. Together, these effects help neurons adapt to changing input conditions.
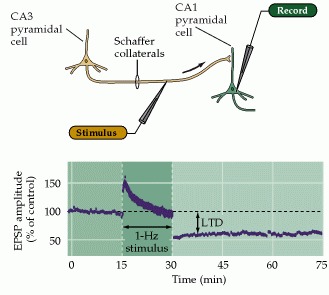
Another class of plasticity involves long term effects. Long term potentiation (LTP) is the persistent strengthening of synapses between neurons based on recent activity patterns. It is thought to be a key cellular mechanism for learning and memory. In glutamatergic synapses LTP is associated with increased postsynaptic response via ionotropic AMPA receptors, and it is also associated with the structural remodeling of synapses including an increase in the size of dendritic spines. The mechanism of LTP is somewhat complex, involving another set of metabotropic NMDA receptors. Depolarization causes the magnesium ions to move away from the NMDA channels, opening them and allowing calcium influx. In turn, the calcium triggers intracellular messengers that case more AMPA receptors to be inserted into the postsynaptic membrane. LTP is an important feature of hippocampal CA1 neurons, and some forms like mossy-fiber LTP in the cerebellum are NMDA-independent. LTP may proceed in multiple phases, for example an early phase that is independent of protein synthesis, and a late phase that requires gene transcription and protein synthesis for structural changes in the synapse. Long term depression (LTD) is the opposite of LTP, often involving the internalization (and degredation or recycling) of AMPA receptors. LTD also causes structural changes in the synapse, including the shrinkage of dendritic spines, and may be involved in the synaptic pruning process during development. LTD occurs in the synapses between the Schaeffer collaterals and CA1 neurons in the hippocampus, as a result of prolonged low frequency stimulation rather than the intense high frequency stimulation that causes LTP. Stimulation of Schaeffer collaterals at 1 Hz for 15 minutes causes depression that lasts for hours.
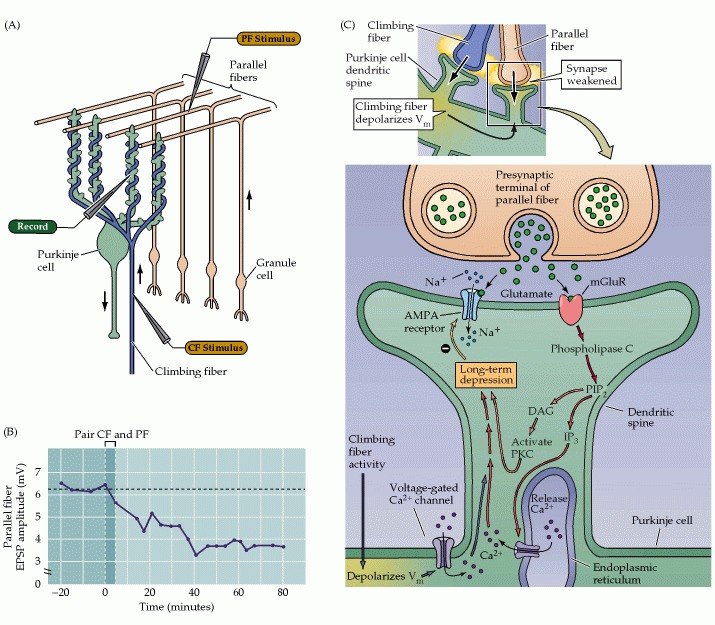
LTP and LTD complement each other. LTP can erase the depressive effects of LTD, and LTD can reset long term potentiation. This provides a perfect complementary pair of operations for controlling a short term memory buffer. LTP can program long-lasting information into synapses, and LTD can erase it. A somewhat different mechanism occurs in the cerebellum, where LTD in the Purkinje cells can follow simultaneous stimulation of parallel fibers and climbing fibers. The figures compare LTD in the hippocampus and cerebellum.
Various learning mechanisms in combination can create sophisticated learning rules. For example the biphasic characteristic of spike timing-dependent plasticity (STDP) can be built from a combination of LTD and LTP. Synaptic changes can occur either homosynaptically (within the same synapse) or heterosynaptically (based on simultaneous events in two or more different synapses). For homosynaptic modifications, it is important that the synapse be isolated from the extracellular environment and from the rest of the neuron's intracellular milieu. This is because synaptic modifications depend heavily on ion fluxes, and the environment at large is too volatile for sensitive synaptic updates. Heterosynaptic activity requires communication between neighboring synapses, which can occur in the form of passive membrane transmission in neurons without spiny synapses, or dendritic mini-spike in spine-laden neurons with active dendrites.
The first thing we'd like to consider is the "burning in" of information. The basic principle is easy enough - every time we show the network an image, the network will adjust its synaptic weights to "represent" the image. This is nothing more than a simple learning rule than changes weights according to luminance, contrast, or color (we're not talking about moving images yet, we'll get to that later). The exact action of synaptic modifications depends heavily on the network structure and the network geometry. Let's say I have an image, and I show it to the network, and now I'd like the network to recall the stored image. To do this, the image details have to be "burned in" to the synapses, in such a way that a representation of the same stimulus causes a large response, whereas the presentation of any other stimulus causes a smaller response (or no response at all). But there's still the problem of readout. In a feed-forward network, the output is a classification, so the final layer is often run through a soft-max function that generates a "one-hot" map. This way, one and only one output results, unless the network can't recognize the image in which case there is no output at all. A different kind of storage occurs in a self-recurrent "attractor network", where the individuation of input categories results in a configuration of dynamic attractors that can be used to handle the reconstruction of noisy images and the similarity between partial images. These types of architectures can support both auto-associative and hetero-associative memory.
We've already seen three different networks that can "memorize" data, specifically the Perceptron, the Hopfield network, and the Kohonen self-organizing map. Let's examine more closely the synaptic update rules that make these systems tick. In the Perceptron, the learning rule is usually kept very simple, it's either the linear distance or the mean square distance from the estimated data to the actual data. The Hopfield network is also straightforward, the synapses are updated based on an energy function that applies an error signal to each synapse on the basis of the product of the pre- and post-synaptic activities. Which begs a question... can neurons multiply? We know they can add signals along the membrane, but is there a way to get an actual multiplication so we can build modulators and demodulators?
The answer, fortunately, is yes - neurons can multiply. Not only that but they can do it in several ways, and which is most useful depends on the application. For example in covariance-driven networks, the actual signal level may not be as important as the simultaneous timing, because the denominators get scaled anyway, in a different process that occurs after the fact - so we don't really need to scale them twice. When a synapse changes weight in a Hopfield network, the energy surface changes shape. As the shape changes, the location of maxima and minima change. So when the network settles into its lowest energy state, the weight matrix will determine where it lands. This is a very useful form of learning because it's entirely local, that is to say it depends only on the activity in individual synapses, plus the energy in the network. On the other hand, the Kohonen self-organizing map uses a different learning rule. In a Kohonen SOM, there is competitive learning using a "winner take all" rule. This means that only the strongest responding neuron will have its synapses updated. To accomplish this, after we multiply the input by the weight matrix, we have to scan the output activity levels, to determine the winner. In turn this means that we can update a Hopfield network neuron by neuron, but we have to update a Kohonen network on a cycle. In the Kohonen network, we have to scan the outputs each time before we update the weight matrix. This is non-biological because real neurons don't do that - and fortunately there are other ways of building a Kohonen network that don't require this non-biological out-of-band scanning activity.
The Role Of Astrocytes In Data StorageIn biological systems, in many cases, short term plasticity is linked to calcium ion channels in the postsynaptic membrane, which means it's very likely they'll be affected by astrocytes in tripartite synapses. Astrocytes are large cells, one astrocyte can wrap itself around 100,000 synapses - so if there is involvement of astrocytes, we can look for "regional" influences. Such regional influences can be important in everything from determining regional energy functions, to determining regional areas of criticality, to encoding local features in regions of the network.
As already indicated in the previous section on neurons, astrocytes respond to local calcium levels and may also have both ionotropic and metabotropic glutamate receptors. One of their roles is thought to be cleaning up after glutamate spillover, however astrocytes are linked by gap junctions and therefore form an electrical syncytium, and they are known to be involved in programmed cell death by the rapid generation and transmission of directional and geometrically focused electrical waves. These phenomena indicate complex signaling mechanisms that have barely been explored. Astrocytes are an open frontier for meaningful research in both neuroscience and machine learning.
The Time Course of Data StorageThe information coming out of a synapse "diffuses" in time. Only a little, but nevertheless the amount is significant. A firing "event" becomes a signal about two milliseconds in duration, with a peak at a delay of about a millisecond. During this two millisecond synaptic event, the postsynaptic membrane responds with a time course to the input. What happens after that, depends on the state of the rest of the membrane. It is therefore logical that the presynaptic system could benefit from knowing the state of the postsynaptic neurons, before sending them any signals. The coordination of such exchanges is the domain of both individual synapses and network population dynamics. The neuron's state always depends on the state of the extracellular milieu, and most of the time this will in turn be influenced by population rhythms (like alpha and theta waves).
There is plenty of evidence that subthreshold membrane oscillations in the post-synaptic neuron will cause the transmission of an input to "wait" until the next peak. This is an important phenomenon that can have a dramatic impact on the signal processing in a neural network. In general, introducing delays (conduction delays, processing delays) into a neural network will cause its dynamics to change. Systems that were previously well behaved will suddenly become chaotic and vice versa. The effects of these delays are well known from control systems theory, and in fact this discipline is indispensible for neuroscientists, very little can be understood about a neural network without understanding its dynamics.
In keeping with the earlier observation on images, the synchronous nature of an image presentation should be preserved as much as possible during the transmission through the visual system. Some stability is usually required for a neural network to process an input, because any form of filtering or optimization (even simple lateral inhibition) takes time. When there are multiple channels representing an input stream, this cautionary principle applies most strongly to the information within each individual channel. For example in the retina, the initial input stream is handled by a set of electrical syncytia, but the moment this information is encoded into spiking neurons, the movement information is segregated into a separate channel - which is a whole lot better than having a blurred image when we're trying to figure out where the edges are!
As mentioned in the section on visual memory, there are three times frames that are important at the systemic level: working memory that lasts seconds, episodic memory that lasts minutes, and long term memory that lasts forever. These are three different processes in the brain, with different mechanisms. Working memory involves a slight persistence in the memory "trace", which can easily be explained by the time course of ordinary synaptic events and doesn't necessarily have to involve plasticity per se, although there could be some STP/D-type activity within the same time frame. Episodic memory is much more complicated, it involves phase encoding and an extensive subsystem related to attention, which selects the information that should be stored and ignores the rest. We still don't know how the consolidation process into long term memory works, even though we're beginning to be informed by the biochemistry of transcription factors and their actions in the synapse and in the spine apparatus. The first two kinds of memory have no counterpart in machine learning so far, although the machine learning community is beginning to explore the meaning of attention, with transformers and other clever architectures that essentially "create a timeline with memory" inside the machine.
Population CodesAs a general rule, whenever something is encoded, it eventually needs to be decoded. This concept applies specifically to the phase encoding we've talked about in several previous sections. Phase encoding results in a "population code", because the encoding wave (theta) moves across the input structure topographically. When the information in a phase encoded signal needs to be recovered, the original encoding wave can be used to extract the original spike sequence. However in real brains, the original encoding wave is almost never available. Instead we have to settle for something "like it", which is often sufficient.
Sometimes, population codes "emerge" from the network on the basis of the neural wiring. A simple example of this was given in the auditory system of the barn owl, where the precise localization of sounds in space is determined by neural delay lines in the cochlear pathways. A population code simply means that the postsynaptic network needs to read non-local information. To a certain extent this can be handled with convergence and divergence in the network wiring, and to a certain extent it can also be handled with hot spots and regional Hamiltonians. The concept of a hot spot in a region of the network is shown in the figure.

This architecture lends itself quite nicely to the modularization of criticality and network "phases" (here used in the sense of ice-water-steam rather than oscillatory activity). A region in a critical phase can behave quite differently from a subcritical region. The two types of regions can communicate with each other in some interesting ways, and criticality can be useful for computation to the extent it can be controlled.
Next: Computational Mechanisms |