As mentioned already, there are two "streams" of visual processing in the human brain, a ventral stream related to "what" an object is, and a dorsal stream related to "where" it is. However in the context of a neural timeline mapping brain electrical activity, we can note something important about the concept of an "object", in that it's invariant with respect to time (whereas its attributes, like position and orientation and velocity, may not be). The concept of an object as an invariant abstraction one can label and attach a name to, has important ramifications in relation to a timeline mapping, because the invariances have to be specifically separated from the other information, which requires specialized neural processing. Anatomy of the Visual StreamsFrom the primary visual cortex, the visual signal feeds forward into V2, the secondary visual cortex. V2 is like a shell that surrounds V1. It has very specific architecture, that treats inputs from ocular dominance columns, orientation columns, and blobs differently. 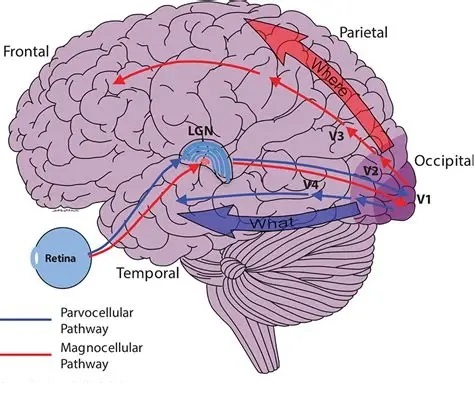 In addition to the red and blue arrows in the figure above, there is an area sandwiched between them, that is shared by both streams. This area includes the MT and MST areas handling motion perception, the face recognition area, and other shared functions that need to be "prepared" before being fed into the streams. The figure shows some of the identified areas of the visual cortex.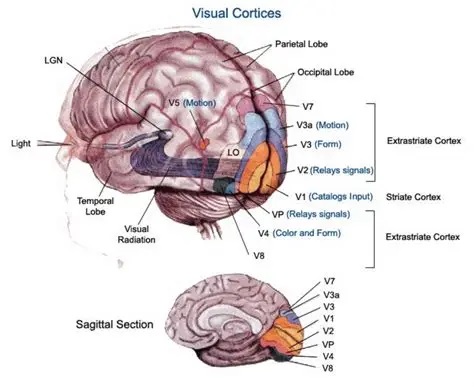 A flattened map of the human visual cortex is shown below, indicating many of the relevant areas.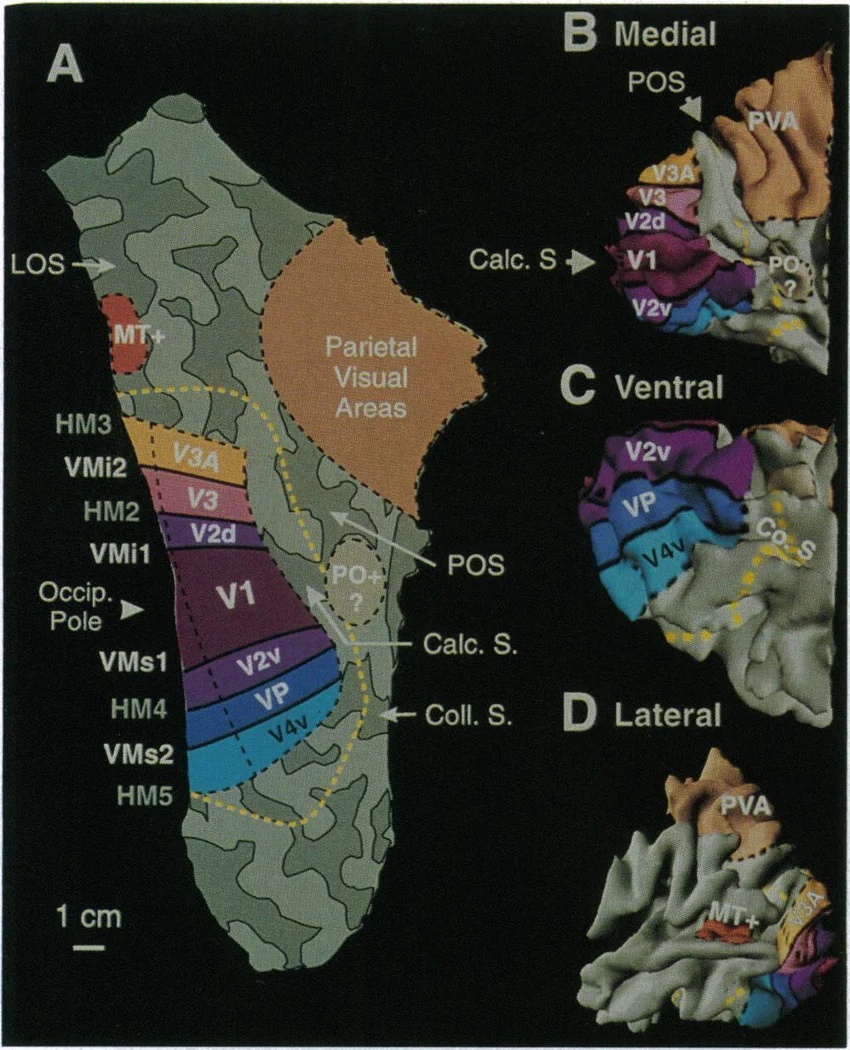 Here is a side view: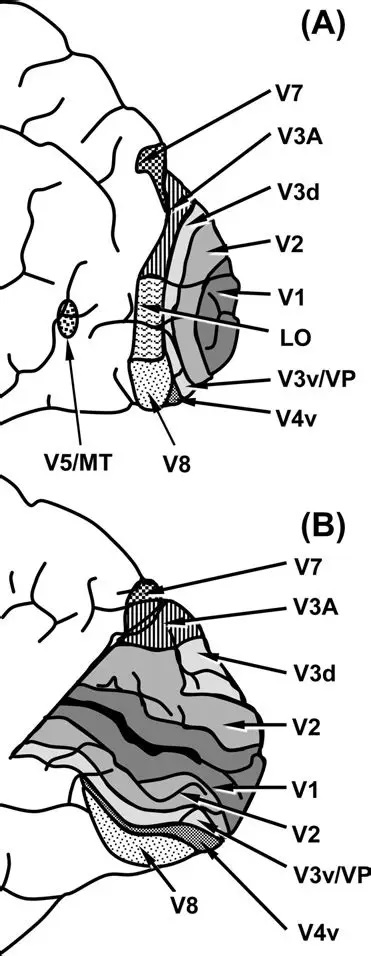 And here is a broader view: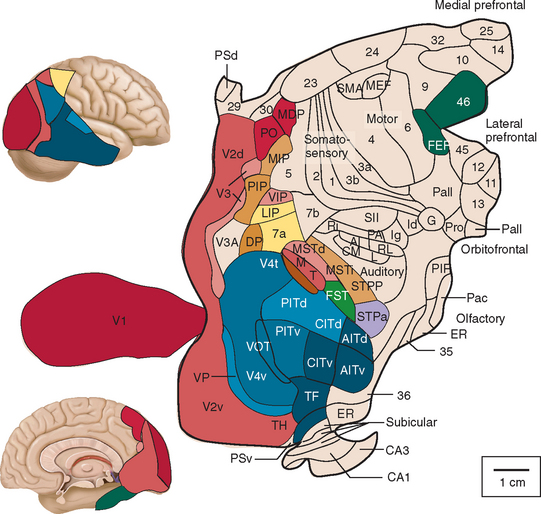 Temporal Lobe and the Ventral StreamThe ventral stream handles object recognition, which is a primary function of the inferior temporal cortex (Area IT in the maps above, including PIT, CIT, and AIT). Objects have semantic meaning, and indeed there is a relationship between IT and Wernicke's area, its counterpart in the auditory realm. From a visual standpoint, objects have certain consistent characteristics, for instance the colors are uniform and move together with the object, the corners mostly have internal angles and the surfaces are mostly curved inwards, and the statistics of the object move along with the object, for example if there is internal motion (like on a wet ball, or if an insect is on it) the motion will move with the ball. 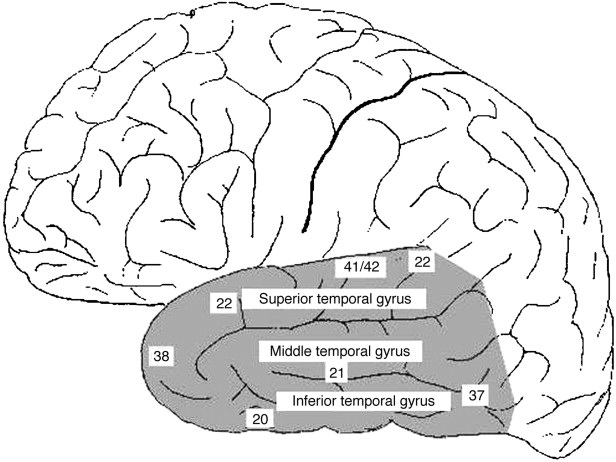 Area IT is a major source of input to the scene mapping circuitry in the area around the hippocampus. IT sends axons into the perirhinal cortex and entorhinal cortex, both of which are crucial for scene mapping and navigation. This area around the hippocampus includes many groups of cells dedicated to specific functions needed for scene mapping, which requires knowledge of "which object is at which location". Area IT provides the object-related information, and the spatial layout and motion of objects is provided by the parietal lobe.Parietal Lobe and the Dorsal StreamObjects are invariant, but their properties are not. Real objects that appear in the visual field are "examples" of abstract objects that are stored in memory. While an object is present in the visual field, it's always the same object, but its properties change, its shape depends on the viewing angle, and its textures depend on lighting and shadows. The "where" stream tracks the variant properties of objects in the visual field. A lot of this tracking has to do with motion, keeping track of which parts of a moving image belong to an object. One of the important processing stations in the dorsal stream isarea MT in the middle temporal lobe, which handles motion using the input passed up through the M channel in early visual processing. Area MT is heavily connected into the oculomotor system at the level of the superior colliculus, it is able to target the eyes to objects moving in the visual field. From area MT, fibers enter the spatial processing areas in the parietal lobe, including area 7 in the superior parietal lobule and the retrosplenial area which includes portions of the area called LIP in the inferior parietal lobule. LIP is also connected with the oculomotor system. It is able to guide the eyes in depth as well as vertically and horizontally. Both of these areas (MT and LIP) are closely related to the dorsal attention system, and that's an interesting discussion because of its relationship to transformer machines (or lack of relationship, in some cases). The figure shows some of the areas hovering around the intraparietal area that are involved in the "where" stream.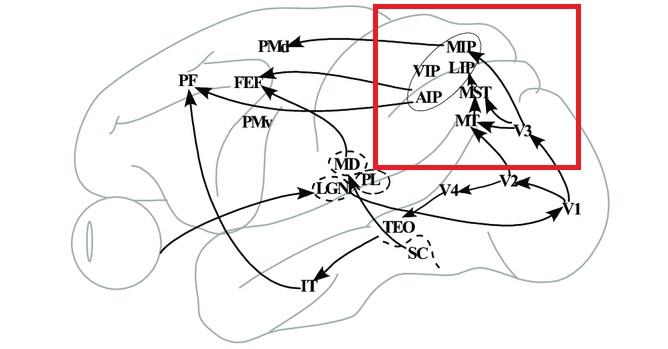 (figure from Shimegi et al 2014) The parietal lobe, in addition to being involved with the mapping of visual space, is also involved in the spatial orientation of the organism within its environment, and that includes the position of the body as well as its parts (head, neck, eyes, and so on). Orienting movements related to visual attention frequently involve neck, head, and whole-body movements. Area MT and the areas of the parietal lobe involved in the "where" stream organize visually guided action, things like reaching, and orienting. In the parietal lobe, the first determination is made of the position of objects in space relative to the organism. This is done from and in an egocentric reference frame, that is to say, the information from the two eyes is combined on the basis of disparity to determine depth in the visual field, and the three dimensional coordinates of objects and their motions are mapped in a cyclopean manner into a geometry where the organism is at the origin. Combining the StreamsThe dorsal and ventral streams come together in the area around the hippocampus, that handles scene mapping, navigation, and short term episodic memory. This area transforms the egocentric reference frame in several ways. One of its basic functions is to generate an allocentric "place map" that is complementary to the egocentric frame. This place map likely engages the "parahippocampal place area". Another of its basic functions is to provide context for a scene, for example the same object that is rewarding in one scene could be aversive in another. The figure shows the combining of the dorsal and ventral visual streams at the level of the entorhinal cortex. In this figure, HPC is the hippocampus.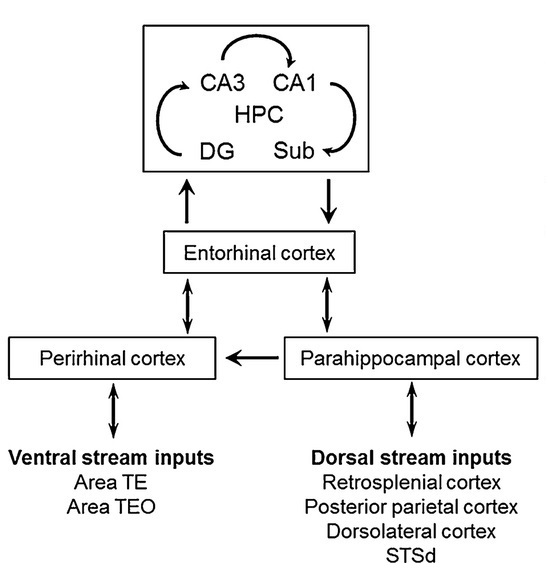 (figure from Elward & Vargha-Khadem 2018 - CC 4.0) The conversion between egocentric and allocentric reference frames seems to occur in and around the entorhinal cortex. This area contains the "grid cells" that map allocentric space, and the "ramp cells" that encode relationships in time. There are also cells that respond to the boundaries of scenes, things like walls, places beyond which the organism can not see. By the time this information reaches the hippocampus, it is fully allocentric, there are "place cells" that only respond when the organism is at a specific location in the allocentric map. 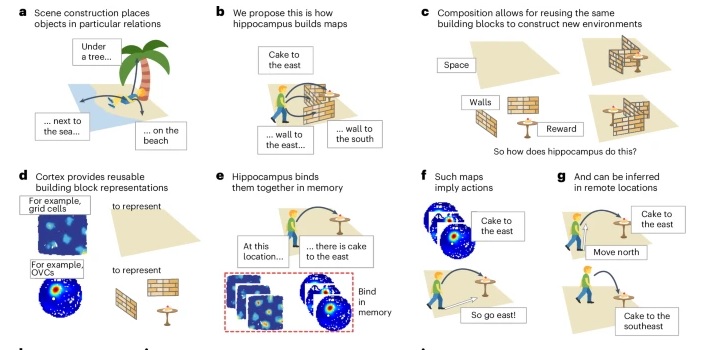 (figure from Bakermans et al 2025) To build a scene, the brain combines information from the "where" pathways and the "what" pathways. Relative to episodic memory, an episode can be considered as a collection of scenes. A scene could be something navigable, like a maze, where the objects all stay in one place but different views create different visual configurations. Or, it could be something relatively static like a room in one's own house, where one can sometimes find things without even looking. It could also be a collection of information around a memorable event, like "I was petting the cat and then it bit me". This figure shows some of the circuitry around "scene reconstruction" using visual information of various kinds.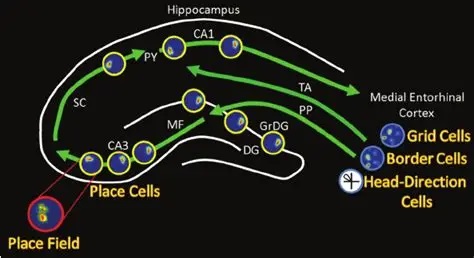 The hippocampal formation is connected into adjoining and upstream brain areas in a wide variety of ways. The major pathway that interests us is the reciprocal connection with the prefrontal cortex, however there are also direct connections with the amygdala, nucleus accumbens, mammillary bodies, cingulate gyrus, and a host of other important brain structures. One of the primary features of hippocampal output is its "phase encoding" of information for these areas, which we'll look at in detail in the section on computation. This figure shows some of the fascinating anatomy associated with the hippocampal connections.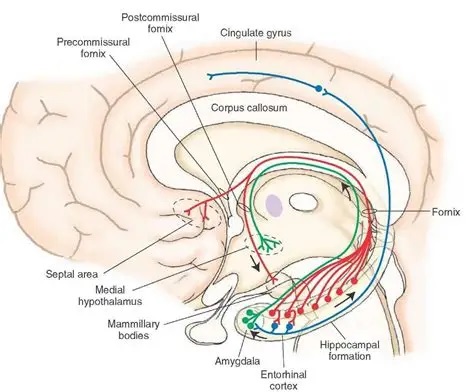 Up until the hippocampus, the requirements for network connectivity through the early visual layers seems to be pretty straightforward. The mapping of scenes from an egocentric viewpoint can be handled by a simple serial network, as shown in the figure.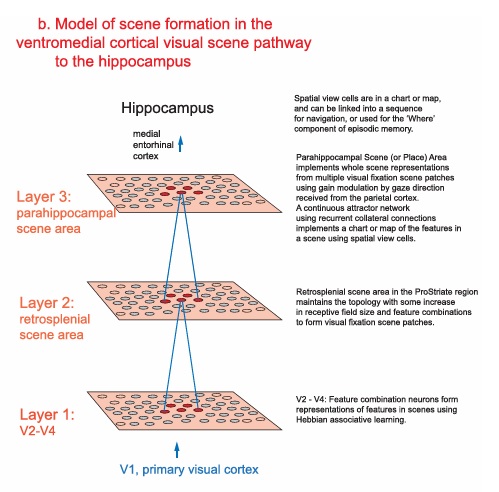 (figure from Rolls 2025) Even the hippocampus itself seems to be anatomically straightforward (we'll look at it in greater detail on the next page). The complexity so far seems to lie in the phase encoding mechanism, which is not yet fully understood. The functional connectivity of the visual pathways into the hippocampal area is shown in the figures below, as determined by magnetoencephalography and diffusion tractography.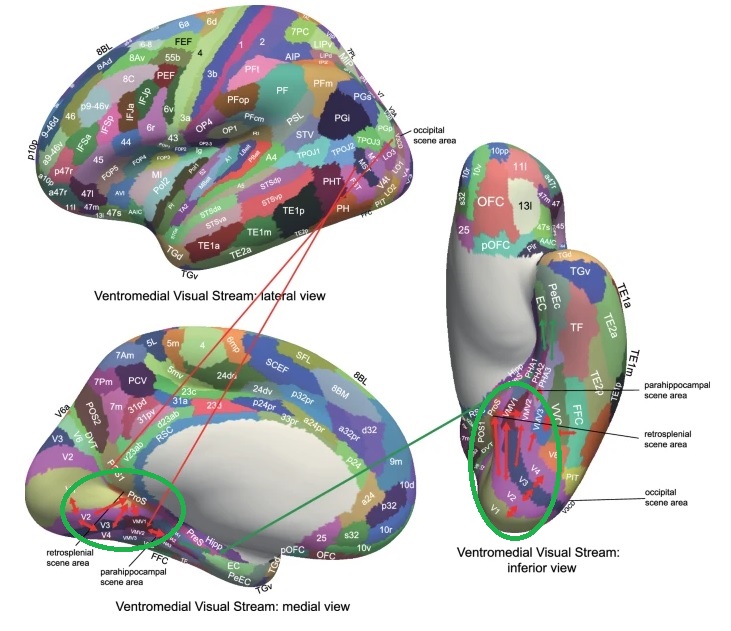 (figure from Rolls et al 2024) 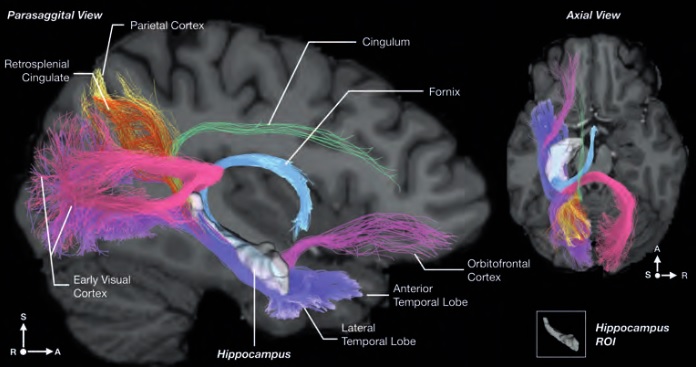 (figure from Rolls 2023) Visual AttentionThe overall pattern of visual cerebral organization is that anything that needs to be perceived is represented explicitly. There are more than 20 retinotopic maps in the human visual cortex, many of these are tiny and very specific. For example the figures below show the "fusiform face area" for facial recognition.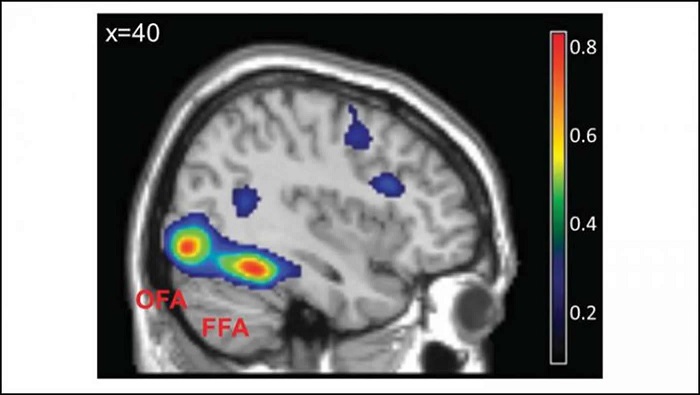 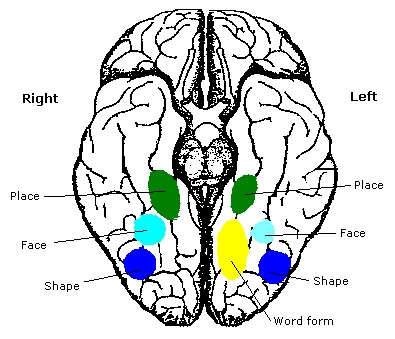 Generally speaking, the dorsal visual stream handles depth perception, spatial orientation, and the location and movement of objects in space. Whereas, the ventral stream handles object recognition, and in that capacity is very closely associated with the act of reading and deciphering printed text. This is an interesting dichotomy because reading involves a lot of motion, however it's coordinated internally by eye movements, rather than externally by visual stimuli. In the visual system, there is a separation of motion and position related information as early as the retina. P, M, and K channels are maintained faithfully through the LGN and V1, and mapped in a regular manner into V2. V2 is where the visual streams begin to split up, and it is also the first visual cortical area responding heavily to visual attention. Responsiveness in the context of attention is usually measured by an increase in firing rate to the attended stimulus - a "gain" relative to the unattended case. Visual attention is related to (and possibly coordinated by) the pulvinar nucleus of the thalamus, with some participation from the mediodorsal nucleus. Both of these thalamic nuclei project to the frontal eye fields, but the pulvinar is mainly related to visually guided attention, whereas MD has more to do with voluntary eye movements. The pulvinar is heavily connected with all of the higher visual cortical areas, including area MT that processes motion. It interfaces between the dorsal and ventral attention streams. Portions of it connect to both the ventral visual stream and the dorsal visual stream. Returning to the brain, there are massive projections from almost all areas of the visual cortex to the pulvinar area of the thalamus, and the frontal eye fields. The pulvinar is related to attention in various modalities, while the frontal eye fields initiate voluntary saccades even in the absence of visual stimuli. The pulvinar receives direct retinotopic projections from the superior colliculus, which we'll discuss in detail in the next section on eye movements, and it's reciprocally connected with all the cortical areas that feed into the superior colliculus, including the area MT, area LIP, and the frontal eye fields. Next: Visual Memory |